Evals Framework
You can't improve what you can't measure. Teams that ship LLM products without rigorous evals are flying blind — they don't know if the new prompt is better, if the model update degraded a capability, or if the product is even achieving its stated goal. At mature AI labs, every model change is gated on eval results; a regression in a single eval benchmark can block a release. The challenge with LLM evaluation is that outputs are open-ended text — you can't just check for equality. McNemar's test, bootstrap CIs, and Cohen's κ give rigorous statistical grounding to pairwise comparisons, and LLM-as-judge unlocks scalable evaluation for tasks where automated metrics fail. This lesson covers the statistical machinery of eval pipelines and implements a complete LLM judge framework.
Theory
ECE measures mean absolute deviation between judge and human score distributions. A biased judge over-scores — sycophantic toward high-quality-looking text even when content is flawed.
You can't trust your own judgment about whether your model is improving — confirmation bias is too strong. Evals are the forcing function: they measure what the model actually does on a representative sample, not what you hope it does. The statistical machinery below (McNemar's test, bootstrap CIs, Cohen's κ) exists for one reason: to tell you whether an observed difference is real or noise, so you can make shipping decisions you can defend.
Evaluation as Hypothesis Testing
The core question: "Is model A better than model B?" This is a paired hypothesis test.
Null hypothesis : models A and B have the same performance. For eval examples, the test statistic under McNemar's test (for binary outcomes):
where = number of examples where A correct, B wrong; = reverse. rejects .
McNemar's test uses only the discordant pairs ( and ) — examples where A and B disagree — because concordant pairs carry no information about which model is better. If both models get an example right, that tells you nothing about their relative quality; same for both getting it wrong. The test statistic is a chi-squared test on the 2×2 table of disagreements. This is why McNemar's is the right test for comparing two classifiers on the same evaluation set, rather than a standard two-sample proportion test.
Bootstrap Confidence Intervals
For any metric (accuracy, BLEU, win rate), bootstrap gives distribution-free confidence intervals:
import numpy as np
def bootstrap_ci(scores: list[float], n_boot: int = 1000, alpha: float = 0.05) -> tuple:
means = [np.mean(np.random.choice(scores, len(scores))) for _ in range(n_boot)]
return np.percentile(means, [100*alpha/2, 100*(1-alpha/2)])
scores = [0.85, 0.92, 0.78, 0.91, 0.88, 0.76, 0.95, 0.83]
lo, hi = bootstrap_ci(scores)
print(f"Mean: {np.mean(scores):.3f}, 95% CI: [{lo:.3f}, {hi:.3f}]")
# Mean: 0.860, 95% CI: [0.796, 0.918]Inter-Rater Reliability
When using human annotators or LLM judges, measure agreement with Cohen's κ:
where is observed agreement and is expected chance agreement. Interpretation:
- : slight (judges disagree significantly)
- –: fair
- –: substantial
- : near-perfect
LLM-as-judge vs human annotators typically achieves – for clear quality dimensions.
"Model A gets 87.3% vs Model B's 86.1%" is meaningless without confidence intervals. On 200 examples, these would have overlapping 95% CIs — the difference is not statistically significant. Always report CIs, not just means.
Walkthrough
Building an Eval Harness
import anthropic
import json
from pathlib import Path
from dataclasses import dataclass
client = anthropic.Anthropic()
@dataclass
class EvalExample:
question: str
reference: str | None = None
context: str | None = None
@dataclass
class EvalResult:
question: str
response: str
score: float | None = None
judgment: str | None = None
def run_eval(
examples: list[EvalExample],
system_prompt: str,
model: str = "claude-sonnet-4-6",
) -> list[EvalResult]:
results = []
for ex in examples:
messages = [{"role": "user", "content": ex.question}]
if ex.context:
messages[0]["content"] = f"Context: {ex.context}\n\nQuestion: {ex.question}"
response = client.messages.create(
model=model, max_tokens=1024,
system=system_prompt, messages=messages,
)
results.append(EvalResult(
question=ex.question,
response=response.content[0].text,
))
return resultsLLM-as-Judge
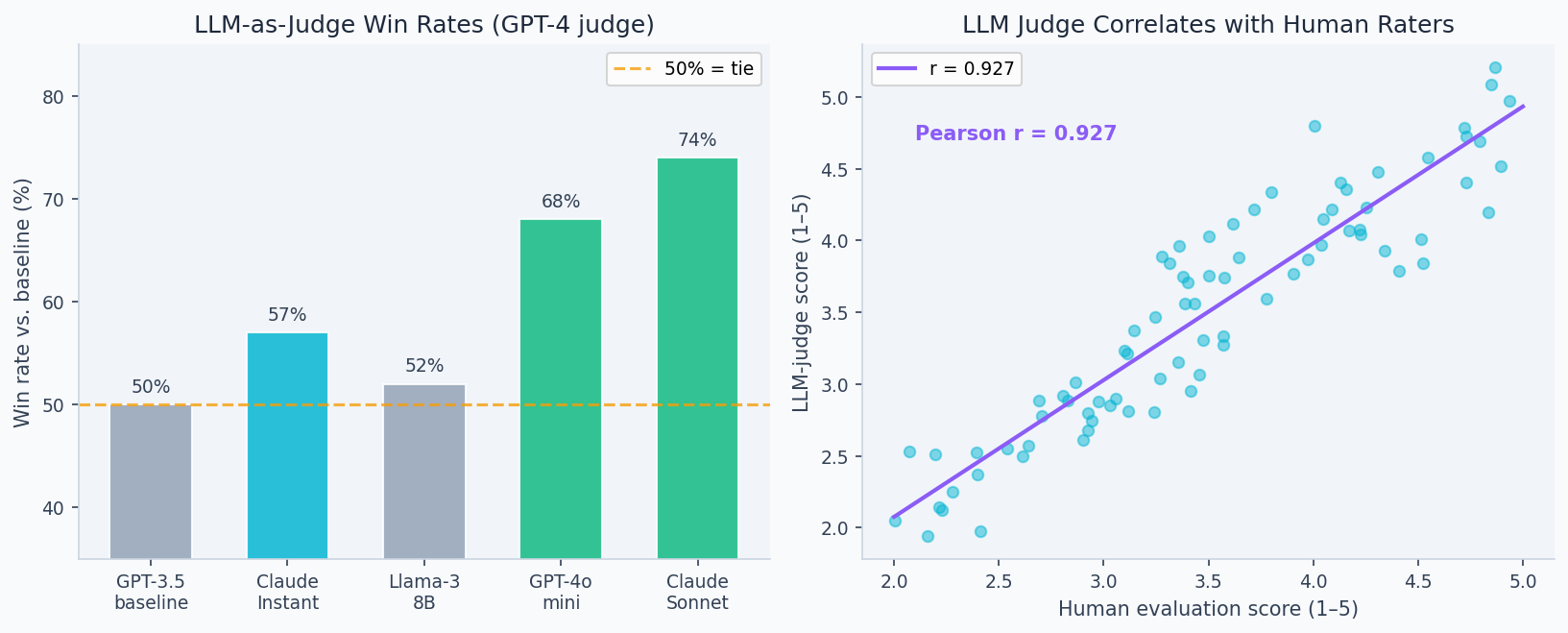
The left panel shows pairwise win rates across evaluation dimensions (helpfulness, accuracy, safety). The right panel shows human-judge correlation: well-calibrated LLM judges (GPT-4, Claude) achieve 0.8+ Spearman correlation with human preferences on most tasks — sufficient for catching regressions, though not for final safety decisions.
JUDGE_PROMPT = """You are evaluating an AI assistant's response.
Question: {question}
Reference answer: {reference}
Model response: {response}
Score the response 1-5 on:
- Accuracy (is it factually correct?)
- Completeness (does it fully answer?)
- Conciseness (is it appropriately brief?)
Respond with JSON: {{"accuracy": N, "completeness": N, "conciseness": N, "reasoning": "..."}}"""
def judge_responses(
results: list[EvalResult],
examples: list[EvalExample],
) -> list[EvalResult]:
for result, ex in zip(results, examples):
if not ex.reference:
continue
judgment = client.messages.create(
model="claude-sonnet-4-6", max_tokens=200,
messages=[{"role": "user", "content": JUDGE_PROMPT.format(
question=ex.question,
reference=ex.reference,
response=result.response,
)}]
)
try:
scores = json.loads(judgment.content[0].text)
result.score = (scores["accuracy"] + scores["completeness"] + scores["conciseness"]) / 3
result.judgment = scores.get("reasoning", "")
except:
result.score = 3.0
return resultsMMLU-Style Benchmark
# Multiple-choice evaluation (exact match)
def eval_mcq(
questions: list[dict], # {"question": str, "choices": list, "answer": str}
model: str = "claude-sonnet-4-6",
) -> dict:
correct = 0
for q in questions:
choices_str = "\n".join(f"{chr(65+i)}. {c}" for i, c in enumerate(q["choices"]))
prompt = f"{q['question']}\n\n{choices_str}\n\nAnswer with just the letter (A/B/C/D):"
r = client.messages.create(
model=model, max_tokens=5,
messages=[{"role": "user", "content": prompt}]
)
pred = r.content[0].text.strip()[0].upper()
if pred == q["answer"]:
correct += 1
accuracy = correct / len(questions)
lo, hi = bootstrap_ci([1.0 if q else 0.0 for q in questions])
print(f"Accuracy: {accuracy:.3f} [{lo:.3f}, {hi:.3f}] on {len(questions)} questions")
return {"accuracy": accuracy, "ci": (lo, hi), "n": len(questions)}Analysis & Evaluation
Where Your Intuition Breaks
A high eval score means the model is good at the task. Eval scores measure the model's behavior on the eval distribution — not on your production distribution. The gap between these two distributions is where eval-passing models fail in production. A model can score 95% on your held-out set because the held-out set was drawn from the same distribution as the training prompts; it may score 60% on real user queries that differ in phrasing, domain, or intent. Goodhart's Law applies: once a measure becomes a target, it ceases to be a good measure. Eval suites must evolve as the model and product evolve.
Benchmark Landscape
| Benchmark | Focus | Metric | Size |
|---|---|---|---|
| Massive Multitask Language Understanding (MMLU) | World knowledge (57 subjects) | Accuracy | 14k MCQ |
| HumanEval | Python coding | Pass@1 | 164 problems |
| GSM8K | Grade school math | Accuracy | 1.3k problems |
| MT-Bench | Multi-turn instruction | GPT-4 score (1–10) | 80 questions |
| Holistic Evaluation of Language Models (HELM) | Multi-axis (accuracy + bias + efficiency) | Composite | ~42 scenarios |
| BIG-Bench Hard | Hard reasoning tasks | Accuracy | 6.5k |
Goodhart's Law in Practice
Once a benchmark is used in training data selection or reward model training, models optimize for it specifically. GPT-4 scored 86.4% on MMLU — but when MMLU-like data appears in pretraining, models can "overfit" to question formats without gaining underlying knowledge. Maintain private holdout evals not shared publicly.
Eval Design Principles
- Task-specific: general benchmarks don't predict performance on your actual use case
- Representative: sample from your real input distribution, not just obvious cases
- Adversarial: include edge cases, ambiguous inputs, and known failure modes
- Versioned: track eval dataset version alongside model version
- Blinded: score with multiple methods; compare LLM judge to human ratings
# Eval versioning
eval_config = {
"eval_id": "v1.2.0",
"date": "2026-02-28",
"model": "claude-sonnet-4-6",
"dataset": "support_tickets_v3",
"n_examples": 500,
"metrics": ["accuracy", "f1", "auc"],
"results": {"accuracy": 0.923, "f1": 0.918, "auc": 0.971},
}
Path("eval_results/v1.2.0.json").write_text(json.dumps(eval_config, indent=2))Enjoying these notes?
Get new lessons delivered to your inbox. No spam.