The Alignment Tax
Making a model safe isn't free. When you fine-tune for helpfulness, harmlessness, and honesty, you're pushing the model's parameters away from the pre-training optimum — and that movement costs benchmark performance. The Llama 2 paper quantified this: instruction-tuned Llama 2 scored lower on MMLU and coding benchmarks than the base model. The alignment tax informs everything from training budget allocation (how much RLHF is too much?) to method selection (DPO vs PPO vs CAI, which preserves more capability?). Understanding the KL-capability tradeoff tells you exactly how to reduce the tax: targeted interventions that shift weights only for harmful behaviors, not the whole distribution. This lesson formalizes the tax, covers catastrophic forgetting via EWC, and compares empirical results across methods.
Theory
Every optimization problem has constraints. Aligning a model means adding constraints — "don't say harmful things," "prefer honest responses," "stay helpful" — and constraints always reduce the size of the feasible set. A policy optimizing freely can go anywhere on the capability frontier; an aligned policy can only go where capability and safety overlap. The diagram below shows this Pareto frontier: the best achievable trade-off, and why every alignment method sits somewhere on the curve rather than dominating it.
The alignment tax is the performance cost paid when optimizing a model for human values rather than pure capability. Formally, if we define capability and safety as functions of model parameters :
where for some weight .
The Pareto frontier below shows that capability and safety are not fully opposed — targeted alignment methods (DPO, LoRA fine-tuning) incur a smaller tax than full RLHF-PPO while achieving similar safety scores. The x-axis is a composite capability score (MMLU + HumanEval); the y-axis is a safety eval score:
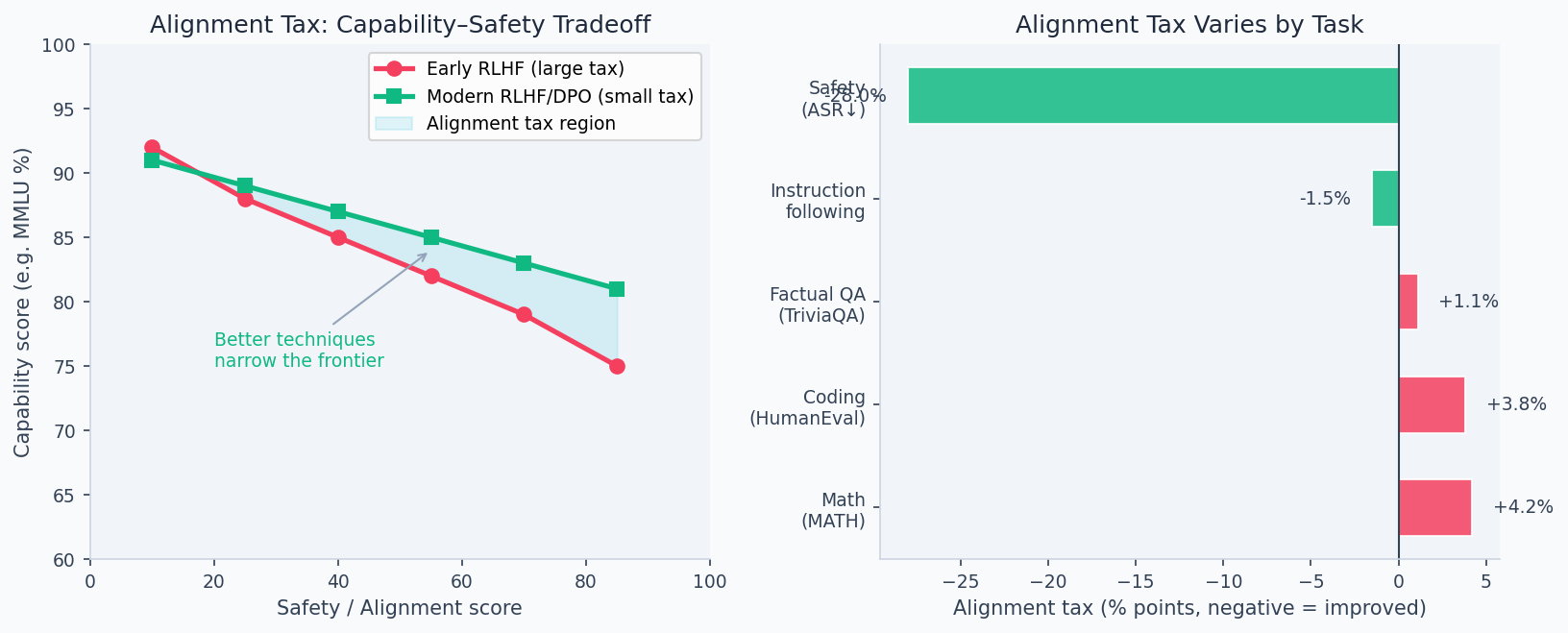
KL-Capability Tradeoff
In the PPO framework, larger KL divergence from the base model correlates with larger alignment tax:
The proportionality to KL distance is not incidental — it's a consequence of how capabilities are stored. Pre-training encodes capabilities in the geometry of the weight space; the SFT checkpoint is a point in that space where the geometry is well-understood. Every gradient step away from that point risks overwriting weights that encode capabilities not targeted by the alignment objective. The KL distance is the right measure because it quantifies how far the new distribution has moved from the one where capabilities were learned.
This implies:
- The alignment tax is roughly proportional to how far we move from the base model
- More targeted interventions (smaller KL, focused on harmful behaviors) preserve more capability
- Constitutional AI and Direct Preference Optimization (DPO) typically incur smaller taxes than full Reinforcement Learning from Human Feedback (RLHF)-PPO
Catastrophic Forgetting
During fine-tuning, gradient updates for new objectives overwrite weights that encode base capabilities. The forgetting rate follows an approximate power law:
Techniques like Elastic Weight Consolidation (EWC) penalize changes to high-Fisher-information parameters:
where is the Fisher information of parameter on the base task.
Parameters important for safety fine-tuning may be completely different from those encoding Massive Multitask Language Understanding (MMLU) knowledge. When we update for safety, we can inadvertently shift weights needed for math reasoning. The Fisher Information Matrix identifies which parameters matter most for the original task.
Walkthrough
Empirical Evidence: InstructGPT (2022)
OpenAI's landmark paper showed:
Model | Human preference | MMLU | TruthfulQA
GPT-3 175B (base) | 20th percentile | 43.9% | 58.2%
InstructGPT 1.3B (SFT) | 50th percentile | 39.1% | 56.8%
InstructGPT 175B (RLHF) | 85th percentile | 42.7% | 61.4%
Key finding: 1.3B InstructGPT was preferred over 175B base GPT-3 by 85% of raters — alignment quality matters more than raw size for user-facing tasks. But both InstructGPT models showed slight MMLU regression.
Llama 2: Quantifying the Tax
# Approximate numbers from Meta's Llama 2 paper (2023)
results = {
"Llama 2 7B (base)": {"MMLU": 45.3, "HumanEval": 12.8, "GSM8K": 11.8},
"Llama 2 7B Chat": {"MMLU": 48.3, "HumanEval": 17.3, "GSM8K": 18.0},
"Llama 2 13B (base)": {"MMLU": 54.8, "HumanEval": 18.3, "GSM8K": 28.7},
"Llama 2 13B Chat": {"MMLU": 54.6, "HumanEval": 23.2, "GSM8K": 29.2},
"Llama 2 70B (base)": {"MMLU": 68.9, "HumanEval": 29.9, "GSM8K": 56.8},
"Llama 2 70B Chat": {"MMLU": 68.8, "HumanEval": 32.9, "GSM8K": 58.4},
}Observation: at 70B scale, the alignment tax is near-zero on most benchmarks. Chat versions even outperform base on HumanEval and GSM8K because instruction fine-tuning improves zero-shot prompting format compliance.
Alignment Methods Comparison
# Approximate alignment tax by method (% points on MMLU)
alignment_tax = {
"SFT only": -0.5, # minimal
"Full RLHF (PPO)": -1.8, # moderate
"Constitutional AI": -0.9, # less than PPO
"DPO": -0.7, # very low
"GRPO": +0.3, # can improve (self-play)
"Best-of-N (64)": 0.0, # no weight change
}DPO and Constitutional AI tend to incur smaller taxes because they stay closer to the SFT model and require fewer gradient updates.
Analysis & Evaluation
Where Your Intuition Breaks
Aligned models are less capable than unaligned models of the same size — the tax is unavoidable. Modern aligned models (Claude 3, GPT-4, Gemini 1.5) outperform unaligned models of similar size on most capability benchmarks. The alignment tax has been shrinking as methods improve: LoRA-based alignment, DPO, and targeted SFT incur taxes of less than 1% on standard benchmarks. Some alignment interventions (SFT on high-quality demonstrations) improve capability on specific tasks by filtering the model's output distribution toward expert-level responses. The tax is real but not fixed — it depends heavily on the alignment method, not on alignment in the abstract.
Strategies to Minimize the Tax
1. Targeted interventions: use behavior-specific datasets rather than broad alignment data. If a model hallucinates facts, fine-tune on factual datasets — not general "harmlessness" data.
2. Low-rank adapters (LoRA): fine-tune only a small subset of parameters. LoRA updates where , , . Rank 8–64 preserves most base capability.
3. ORPO / SimPO: more recent alignment methods that collapse SFT and preference learning into a single pass, reducing forgetting from multiple fine-tuning stages.
4. Merging aligned + base models: linearly interpolate weights . Often recovers capability with minor safety degradation.
Each stage of fine-tuning (pretraining → SFT → RLHF → safety filtering) introduces its own tax. After 4 stages, a 0.5% tax per stage compounds to ~2% total. Monitor capability regressions at each stage of the training pipeline, not just end-to-end.
The Open Problem
No alignment technique has been shown to scale to frontier model capabilities without some form of tax. The central open question in alignment research: can we build models that are simultaneously more helpful and more aligned, rather than trading one for the other?
Evidence from Claude 3, GPT-4, and Gemini 1.5 suggests we're moving in the right direction — modern aligned models outperform older unaligned models of similar size on most benchmarks. But whether this continues as we push toward Artificial General Intelligence (AGI)-level capability remains an open question.
A 5% capability tax on a system that's 100× more capable than today's frontier models is negligible. The tax matters most right now — at current capability levels — because we need alignment techniques that can scale gracefully without sacrificing the properties that make powerful AI valuable.
Enjoying these notes?
Get new lessons delivered to your inbox. No spam.